Assert QA == Developer
¿Es un QA un developer? Me gusta hablar con la gente. Me gusta compartir opiniones. Me gusta debatir. Tras varias conversaciones con compañeros de trabajo, de los que he podido obtener de una forma u otra feedback de lo que creen que es el trabajo de un QA Engineer, me he propuesto a escribir un post que ayude a romper ciertas barreras mentales en el trabajo que creemos que hace un ingeniero de calidad y ver si en realidad es un developer.
Ingeniería de la calidad del software
La realidad es que poca gente conoce lo que es la ingeniería de la calidad. No es algo conocido, no es algo que llame la atención cuando decides estudiar informática, es la realidad.
Cuando un desarrollador habla de un QA, no piensa que desarrolle, no lo trata como un desarrollador. Es más, muchos piensan que los QAs son desarrolladores frustrados, y no es cierto.
¿Porque cuesta tanto ver la ingeniería QA como una rama de la ingeniería del software, del desarrollo?
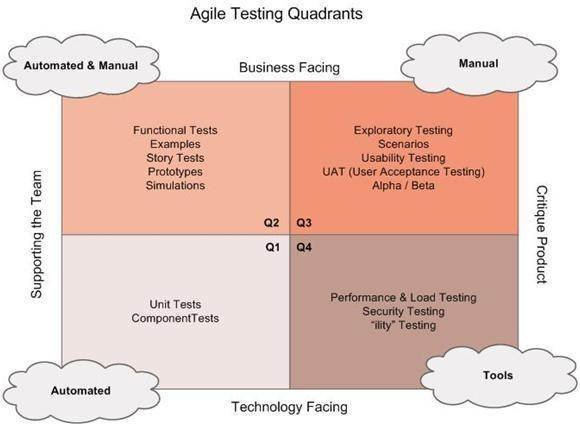
Cuando se piensa únicamente desarrollamos pruebas se está muy equivocado. La calidad del software no solo se garantiza con teses.
Desarrollamos teses, ¡por supuesto que sí! Y en muchas ocasiones la lógica que implementamos en el test puede ser más compleja que el código o la funcionabilidad que probamos. Y si… sabemos lo que son los patrones… es más, los aplicamos.
Para garantizar que el software cumple con los requisitos de calidad exigidos los QAs deben diseñar y aplicar las estrategias de calidad necesarias. Y muy seguramente en esas estrategias se implementen diferentes proyectos, desde automatización de pruebas hasta proyectos más complejos, y adivinad, muchos de ellos habrá que desarrollarlos.
Automatización de pruebas
Automatizar pruebas funcionales no siempre significa automatizar el comportamiento de una funcionalidad mediante UI testing. En muchas ocasiones se requiere hacer pruebas funcionales a nivel de API, o probar funcionalidades cross-aplicación y cross-dispotivo.
Aquí os dejo los enlaces a la presentación y explicación de cómo Uber realiza pruebas cross-aplicación y cross-dispotivo para probar sus aplicaciones mediante Octopus.
POST:
https://eng.uber.com/rescued-by-octopus/
SLIDE:
https://docs.google.com/presentation/d/1vYXhkvgLKun72Ix91LQDDWZQdcY5VOBqKVvI1Y6riYo/pub?slide=id.gd8d657045_0_0
VIDEO:
https://www.youtube.com/watch?v=p6gsssppeT0
Para mi es importante entender que un QA no es una persona dedicada únicamente a automatizar pruebas o a realizar testing. Es un ingeniero capaz de desarrollar las herramientas necesarias que ayuden a garantizar la calidad de la aplicación.
Lo que significa que un QA es un desarrollador especializado en la calidad.
Sí, somos un equipo
Una de las cosas que me dijeron era que si el que desarrollaba la tarea hacia bien su trabajo no tenía por qué meter bugs, y ya que sabía lo que estaba desarrollando y donde afectaba él podría hacer las pruebas, por lo tanto, los QAs sobraban.
Bueno, en un mundo perfecto donde el desarrollador está encantado de probar todo lo que hace, y donde el tiempo de entrega no existe, en el que nunca se equivoca, puede ser…¡pues tampoco! Que te diga coca cola o Samsung que no hacen control de calidad de sus productos… igual sus móviles explotarían.
Es necesario desarrollar estrategias y proyectos que garanticen la calidad de nuestras aplicaciones, equipar al equipo de desarrollo con las herramientas suficientes para hacer código de calidad, para agilizar su desarrollo.
Cada equipo somos piezas del desarrollo. Desarrollo, DevOps, Producto, QA etc.
Conclusiones
Antes de ser QA fuí desarrollador, y hoy en día sigo desarrollando casi al mismo nivel que antes, salvo que antes funcionalidades de una aplicación, y ahora herramientas que garantizan su calidad. ¿Qué diferencia hay?
Los QAs también somos desarrolladores, es la realidad, y primero nos lo tenemos que creer nosotros para que los demás se lo crean.







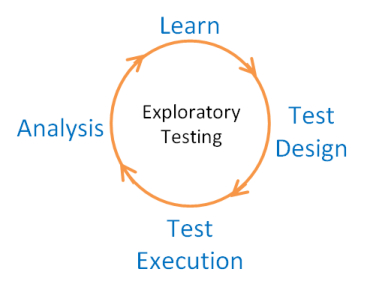 El QA deberá garantizarlas de forma simultanea a medida que va probando la aplicación, es decir, va diseñando las pruebas y ejecutándolas al tiempo que va adquiriendo conocimientos de la aplicación.
El QA deberá garantizarlas de forma simultanea a medida que va probando la aplicación, es decir, va diseñando las pruebas y ejecutándolas al tiempo que va adquiriendo conocimientos de la aplicación.